

How To Assess Distribution Of Panel Data
Panel information regression: a powerful time series modeling technique
Applying econometrics in information science and machine learning bug
In a previous piece, I briefly mentioned about panel data models; and in this mail, I am getting a fleck deeper into information technology with some technical details. Equally I said in that post, econometrics has some of the almost important tools for data scientists' toolbox. It has numerous use cases — from measuring impacts of temperature variability on agriculture to fourth dimension serial data modeling and forecasting.
What's console data?
So what exactly is panel data? Offset, permit's take a look at the following definition:
A panel data is a multi-dimensional data of an observation that is measured repeatedly over time.
This is a ane-liner definition, but a lot to unpack from. This definition implicitly describes three key properties of a panel dataset:
- holding one: the same objects/individuals are observed repeatedly
- property 2: multiple variables are measured of those same individuals/objects
- property 3: the observations take place at multiple points in time
To illustrate these properties the following is a hypothetical (I made it up on the fly) dataset with 4 columns and iv rows.
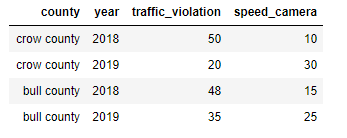
- The dataset contains 4 observations of two (imaginary) US counties— Crow Canton and Bull county (property i).
- For each county, ii variables were measured — the number of speed cameras installed and the number of traffic violations (property 2).
- And finally, measurements took place in 2 different discrete time points — 2018 and 2019 (holding 3).
How absurd!
Panel data regression techniques
I'll now move forth to describe how panel data modeling techniques tin can reply specific questions. Allow'south say using the higher up 4 x 4 dataset we want to respond the following question:
Does number of installed speed cameras impact number of traffic violation cases?
If nosotros run a simple linear OLS regression we should be able to apace check the association — if there is any — between the two variables:
traffic_violation = f(speed_camera)
However, think that this is no ordinary dataset, it'south a panel information. Which ways nosotros can use it far effectively than running a simple OLS regression.
How?
First, we shouldn't forget that the independent variable has 2 other properties — county and yr. Pregnant that there is a variation along individual and fourth dimension dimensions, which we tin capture in more than advanced models that we are calling panel data regression .
There are three main types of panel data models (i.e. estimators) and briefly described beneath are their formulation.
a) Pooled OLS model
Pooled OLS (Ordinary Least Square) model treats a dataset like whatever other cross-sectional data and ignores that the data has a time and individual dimensions. That is why the assumptions are similar to that of ordinary linear regression.
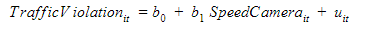
b) Stock-still effects model
While speed camera installation might take an impact on traffic violations, it is besides possible that each individual canton is different in terms of traffic violation considering of reasons other than speed camera (e.g. higher charge per unit of highway patrol?). However, this is not reflected in the above OLS model. Fixed effects models become a step further by taking into account the differences betwixt private entities (counties in our case):

c) Random effects model
In fixed effects model nosotros have controlled for differences between individual counties. Merely what about variables that are constant across individuals only change over time? A random effects model takes into consideration these individual variations too as time dependent variations. The model eliminates biases from variables that are unobserved and change over time.
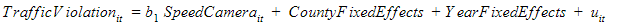
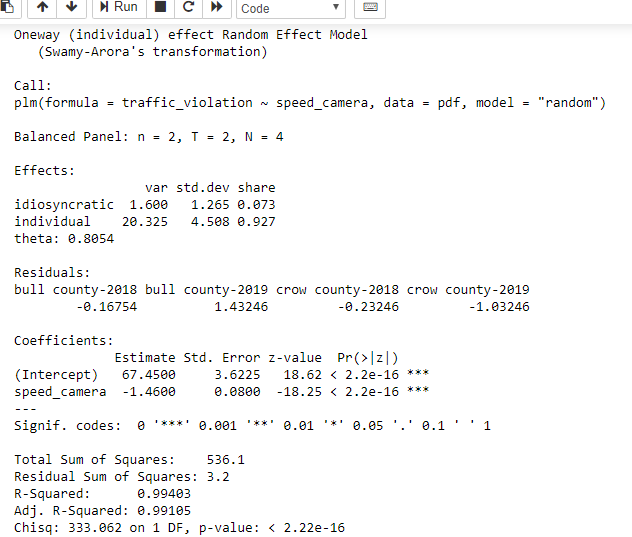
Implementation
Information technology is really but a few lines of codes (assuming that you lot accept done the other fourscore% work of information wrangling!). plm is the best R library in boondocks that implements your model in just 3 like shooting fish in a barrel steps: (1) information technology takes in input the data; (2) converts data into a panel data frame; (three) implements the model as you specify.
# import bundle
library(plm)
# import information
df = read.table("../information.csv")
# convert the information frame to a data format recognizable past `plm`
pdf = pdata.frame(df, alphabetize = c("county", "year"))
# specify and run the model
model = plm(traffic_violation~speed_camera, data = pdf, model = "random") summary(model)
Final notes
Data science is an evolving discipline and is being enriched with diverse tools and techniques coming from many disciplines. Econometrics offers tools which are traditionally used in social and economic research simply are likewise calculation value in data science. For those interested, ii open up access books can go you started in econometrics and advanced social science research:
- Introduction to Econometrics with R and
- Principles of Econometrics with R.
These two books draw complex techniques in an accessible fashion along with applications and implementation in R programming language.

How To Assess Distribution Of Panel Data,
Source: https://towardsdatascience.com/panel-data-regression-a-powerful-time-series-modeling-technique-7509ce043fa8
Posted by: santanathisn1970.blogspot.com
0 Response to "How To Assess Distribution Of Panel Data"
Post a Comment